Data Model
Data Model
An abstraction that organizes elements of data and how they relate to each other. It can easily translate to database modeling, as this is the essential end state.
It's also an iterative process. Data engineers continually reorganize, restructure, and optimize data models to fit the needs of the organization.
Data Modeling process:
- Conceptual
- Logical
- Physical
SQL
Structured Query Language is a domain-specific language used in programming and designed for managing data held in a relational database management system (RDBMS).
DDL
DDL is short name of Data Definition Language, which deals with database schemas and descriptions, of how the data should reside in the database.
- CREATE : to create a database and its objects like (table, index, views, store procedure, function, and triggers)
- ALTER : alters the structure of the existing database
- DROP : delete objects from the database
- TRUNCATE : remove all records from a table, including all spaces allocated for the records are removed
- COMMENT : add comments to the data dictionary
- RENAME : rename an object
DML
DML is short name of Data Manipulation Language which deals with data manipulation and includes most common SQL statements such SELECT, INSERT, UPDATE, DELETE, etc., and it is used to store, modify, retrieve, delete and update data in a database.
- SELECT : retrieve data from a database
- INSERT : insert data into a table
- UPDATE : updates existing data within a table
- DELETE : Delete all records from a database table
- MERGE : UPSERT operation (insert or update)
- CALL : call a PL/SQL or Java subprogram
- EXPLAIN PLAN : interpretation of the data access path
- LOCK TABLE : concurrency Control
DCL
DCL is short name of Data Control Language which includes commands such as GRANT and mostly concerned with rights, permissions and other controls of the database system.
- GRANT : allow users access privileges to the database
- REVOKE : withdraw users access privileges given by using the GRANT command
TCL
TCL is short name of Transaction Control Language which deals with a transaction within a database.
- COMMIT : commits a Transaction
- ROLLBACK : rollback a transaction in case of any error occurs
- SAVEPOINT : to rollback the transaction making points within groups
- SET TRANSACTION : specify characteristics of the transaction
Advantages of Using a Relational Database
- Flexibility for writing in SQL queries: With SQL being the most common database query language.
- Modeling the data not modeling queries
- Ability to do JOINS
- Ability to do aggregations and analytics
- Secondary Indexes available : You have the advantage of being able to add another index to help with quick searching.
- Smaller data volumes: If you have a smaller data volume (and not big data) you can use a relational database for its simplicity.
- ACID Transactions: Allows you to meet a set of properties of database transactions intended to guarantee validity even in the event of errors, power failures, and thus maintain data integrity.
- Easier to change to business requirements
ACID Transactions
Properties of database transactions intended to guarantee validity even in the event of errors or power failures.
- Atomicity: The whole transaction is processed or nothing is processed. A commonly cited example of an atomic transaction is money transactions between two bank accounts. The transaction of transferring money from one account to the other is made up of two operations. First, you have to withdraw money in one account, and second you have to save the withdrawn money to the second account. An atomic transaction, i.e., when either all operations occur or nothing occurs, keeps the database in a consistent state. This ensures that if either of those two operations (withdrawing money from the 1st account or saving the money to the 2nd account) fail, the money is neither lost nor created.
- Consistency: Only transactions that abide by constraints and rules are written into the database, otherwise the database keeps the previous state. The data should be correct across all rows and tables.
- Isolation: Transactions are processed independently and securely, order does not matter. A low level of isolation enables many users to access the data simultaneously, however this also increases the possibilities of concurrency effects (e.g., dirty reads or lost updates). On the other hand, a high level of isolation reduces these chances of concurrency effects, but also uses more system resources and transactions blocking each other.
- Durability: Completed transactions are saved to database even in cases of system failure. A commonly cited example includes tracking flight seat bookings. So once the flight booking records a confirmed seat booking, the seat remains booked even if a system failure occurs
When Not to Use a Relational Database
- Have large amounts of data: Relational Databases are not distributed databases and because of this they can only scale vertically by adding more storage in the machine itself. You are limited by how much you can scale and how much data you can store on one machine. You cannot add more machines like you can in NoSQL databases.
- Need to be able to store different data type formats: Relational databases are not designed to handle unstructured data.
- Need high throughput -- fast reads: While ACID transactions bring benefits, they also slow down the process of reading and writing data. If you need very fast reads and writes, using a relational database may not suit your needs.
- Need a flexible schema: Flexible schema can allow for columns to be added that do not have to be used by every row, saving disk space.
- Need high availability: The fact that relational databases are not distributed (and even when they are, they have a coordinator/worker architecture), they have a single point of failure. When that database goes down, a fail-over to a backup system occurs and takes time.
- Need horizontal scalability: Horizontal scalability is the ability to add more machines or nodes to a system to increase performance and space for data.
NoSQL
NoSQL databases were created to do some of the issues faced with relational databases.
- Apache Cassandra (partition row store): The data is distributed by partitions across nodes or servers and the data is organized in the columns and rows format.
- MongoDB (document store): One of the defining characteristics of a document oriented database is that in addition to the key lookups performed by key-value store, the database also offers an API or query language that retrieves document based on its contents. It's basically easy to do search on documents.
- DynamoDB (key-value store): data is represented as a collection of key and value pairs.
- Apache HBase (wide column store): It also uses tables, rows and columns but unlike a relational database, the names and formats of the columns can vary from row to row in the same table.
- Neo4j (graph databas): it's all about relationships and the data is represented as nodes and edges.
Apache Cassandra
It provides scalability and high availability without compromising performace. Linear Scalability and proven fault-tolerance on commodity hardware or cloud infrastructure make it the perfect platform for mission-critical data.
What type of companies use Apache Cassandra?
Uber uses Apache Cassandra for their entire backend. Netflix uses Apache Cassandra to serve all their videos to customers. Good use cases for NoSQL (and more specifically Apache Cassandra) are :
- Transaction logging (retail, health care)
- Internet of Things (IoT)
- Time series data
- Any workload that is heavy on writes to the database (since Apache Cassandra is optimized for writes).
When to use a NoSQL Database
- Need to be able to store different data type formats: NoSQL was also created to handle different data configurations: structured, semi-structured, and unstructured data. JSON, XML documents can all be handled easily with NoSQL.
- Large amounts of data: Relational Databases are not distributed databases and because of this they can only scale vertically by adding more storage in the machine itself. NoSQL databases were created to be able to be horizontally scalable. The more servers/systems you add to the database the more data that can be hosted with high availability and low latency (fast reads and writes).
- Need horizontal scalability: Horizontal scalability is the ability to add more machines or nodes to a system to increase performance and space for data
- Need high throughput: While ACID transactions bring benefits they also slow down the process of reading and writing data. If you need very fast reads and writes using a relational database may not suit your needs.
- Need a flexible schema: Flexible schema can allow for columns to be added that do not have to be used by every row, saving disk space.
- Need high availability: Relational databases have a single point of failure. When that database goes down, a failover to a backup system must happen and takes time.
When NOT to use a NoSQL Database?
- When you have a small dataset: NoSQL databases were made for big datasets not small datasets and while it works it wasn’t created for that.
- When you need ACID Transactions: If you need a consistent database with ACID transactions, then most NoSQL databases will not be able to serve this need. NoSQL database are eventually consistent and do not provide ACID transactions. However, there are exceptions to it. Some non-relational databases like MongoDB can support ACID transactions.
- When you need the ability to do JOINS across tables: NoSQL does not allow the ability to do JOINS. This is not allowed as this will result in full table scans.
- If you want to be able to do aggregations and analytics
- If you have changing business requirements: Ad-hoc queries are possible but difficult as the data model was done to fix particular queries
- If your queries are not available and you need the flexibility: You need your queries in advance. If those are not available or you will need to be able to have flexibility on how you query your data you might need to stick with a relational database.
Relational Data Model
Importance of Relational Databases:
- Standardization of data model: Once your data is transformed into the rows and columns format, your data is standardized and you can query it with SQL
- Flexibility in adding and altering tables: Relational databases gives you flexibility to add tables, alter tables, add and remove data.
- Data Integrity: Data Integrity is the backbone of using a relational database.
- Standard Query Language (SQL): A standard language can be used to access the data with a predefined language.
- Simplicity : Data is systematically stored and modeled in tabular format.
- Intuitive Organization: The spreadsheet format is intuitive but intuitive to data modeling in relational databases.
Online Analytical Processing (OLAP)
Databases optimized for these workloads allow for complex analytical and ad hoc queries, including aggregations. These type of databases are optimized for reads.
Online Transactional Processing (OLTP)
Databases optimized for these workloads allow for less complex queries in large volume. The types of queries for these databases are read, insert, update, and delete.
The key to remember the difference between OLAP and OLTP is analytics (A) vs transactions (T). If you want to get the price of a shoe then you are using OLTP (this has very little or no aggregations). If you want to know the total stock of shoes a particular store sold, then this requires using OLAP (since this will require aggregations).
Objectives of Normal Form
- To free the database from unwanted insertions, updates, & deletion dependencies
- To reduce the need for refactoring the database as new types of data are introduced
- To make the relational model more informative to users
- To make the database neutral to the query statistics
How to reach First Normal Form (1NF):
- Atomic values: each cell contains unique and single values
- Be able to add data without altering tables
- Separate different relations into different tables
- Keep relationships between tables together with foreign keys
Second Normal Form (2NF):
- Have reached 1NF
- All columns in the table must rely on the Primary Key
Third Normal Form (3NF):
- Must be in 2nd Normal Form
- No transitive dependencies
- Remember, transitive dependencies you are trying to maintain is that to get from A-> C, you want to avoid going through B.
Denormalization
JOINS on the database allow for outstanding flexibility but are extremely slow. If you are dealing with heavy reads on your database, you may want to think about denormalizing your tables. You get your data into normalized form, and then you proceed with denormalization. So, denormalization comes after normalization.
Fact and Dimension Table
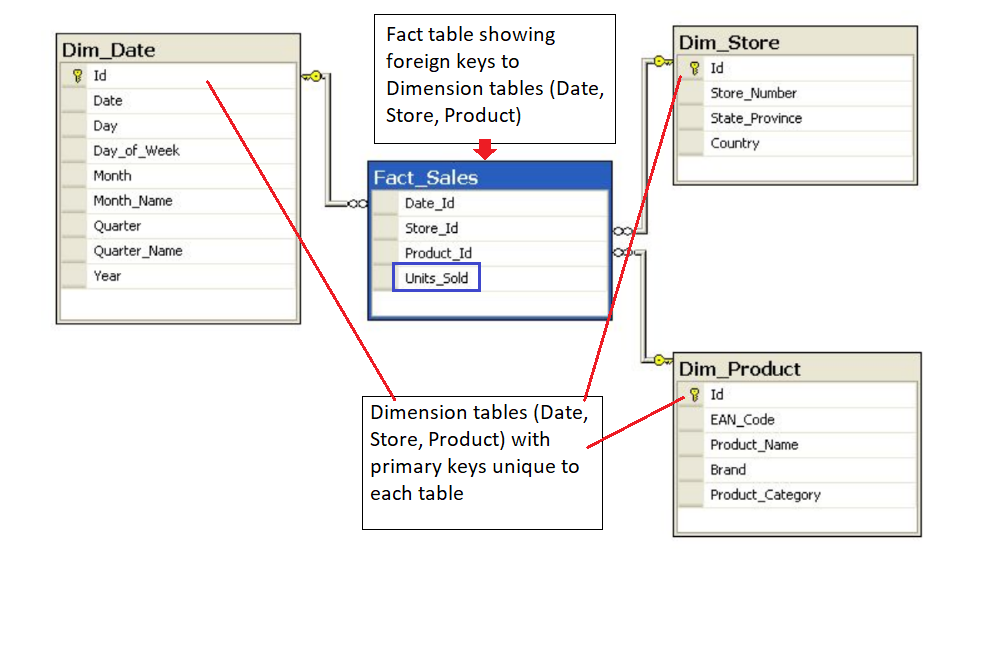
As you can see in the image, the unique primary key for each Dimension table is included in the Fact table.
In this example, it helps to think about the Dimension tables providing the following information:
- Where the product was bought? (Dim_Store table)
- When the product was bought? (Dim_Date table)
- What product was bought? (Dim_Product table)
The Fact table provides the metric of the business process (here Sales).
- How many units of products were bought? (Fact_Sales table)
CAP Theorem
A theorem in computer science that states it is impossible for a distributed data store to simulataneously provide more than two out of the following three guarantees of consisency, availability and partition tolerance.
- Consistency: Every read from the database gets the latest (and correct) piece of data or an error
- Availability: Every request is received and a response is given -- without a guarantee that the data is the latest update
- Partition Tolerance: The system continues to work regardless of losing network connectivity between nodes
Data Modeling in Apache Cassandra:
- Denormalization is not just okay -- it's a must
- Denormalization must be done for fast reads
- Apache Cassandra has been optimized for fast writes
- ALWAYS think Queries first
- One table per query is a great strategy
- Apache Cassandra does not allow for JOINs between tables