Dynamic Programming
The term dynamic programming (DP) refers to a collection of algorithms that can be used to compute optimal policies given a perfect model of the environment as a Markov decision process (MDP).
The key idea of DP, and of reinforcement learning generally, is the use of value functions to organize and structure the search for good policies.
In the dynamic programming setting, the agent has full knowledge of the MDP. (This is much easier than the reinforcement learning setting, where the agent initially knows nothing about how the environment decides state and reward and must learn entirely from interaction how to select actions.)
An Iterative Method
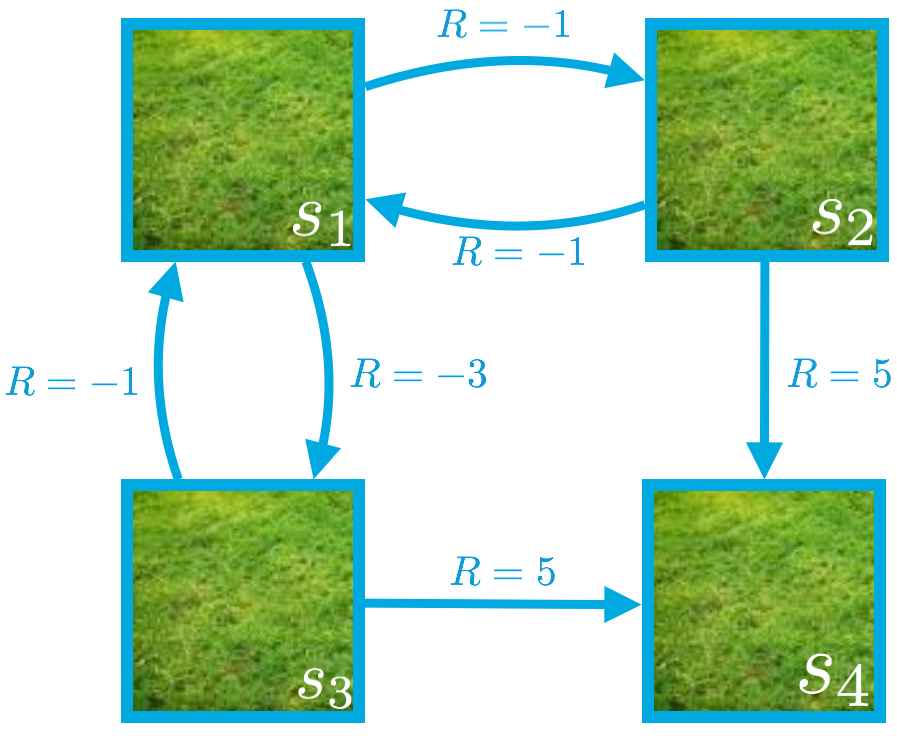
In order to obtain the state-value function corresponding to a policy , we need to solve the system of equations corresponding to the Bellman expectation equation for .
Notes on the Bellman Expectation Equation
for state , we saw that:
We mentioned that this equation follows directly from the Bellman expectation equation for
(The Bellman expectation equation for )
In order to see this, we can begin by looking at what the Bellman expectation equation tells us about the value of state (where we just need to plug in s_1 for state ).
Then, it's possible to derive the equation for state by using the following:
- (When in state s_1, the agent only has two potential actions: down or right.)
- (We are currently examining the policy where the agent goes down with 50% probability and right with 50% probability when in state .)
- (If the agent chooses to go down in state then with 100% probability, the next state is , and the agent receives a reward of -3.)
- (If the agent chooses to go right in state , then with 100% probability, the next state is , and the agent receives a reward of -1.)
- (We chose to set the discount rate to 1 in this gridworld example.)
Notes on Solving the System of Equations
This example serves to illustrate the fact that it is possible to directly solve the system of equations given by the Bellman expectation equation for However, in practice, and especially for much larger Markov decision processes (MDPs), we will instead use an iterative solution approach.
You can directly solve the system of equations:
Since the equations for and are identical, we must have that
Thus, the equations for and can be changed to:
Combining the two latest equations yields
which implies Furthermore,
Thus, the state-value function is given by:
we have discussed how an agent might obtain the state-value function corresponding to a policy .
In the dynamic programming setting, the agent has full knowledge of the Markov decision process (MDP). In this case, it's possible to use the one-step dynamics of the MDP to obtain a system of equations corresponding to the Bellman expectation equation for .
In order to obtain the state-value function, we need only solve the system of equations.
While it is always possible to directly solve the system, we will instead use an iterative solution approach.
The iterative method begins with an initial guess for the value of each state. In particular, we began by assuming that the value of each state was zero.
Then, we looped over the state space and amended the estimate for the state-value function through applying successive update equations.
Recall that denotes the most recent guess for the state-value function, and the update equations are:
The state-value function for the equiprobable random policy is visualized below:
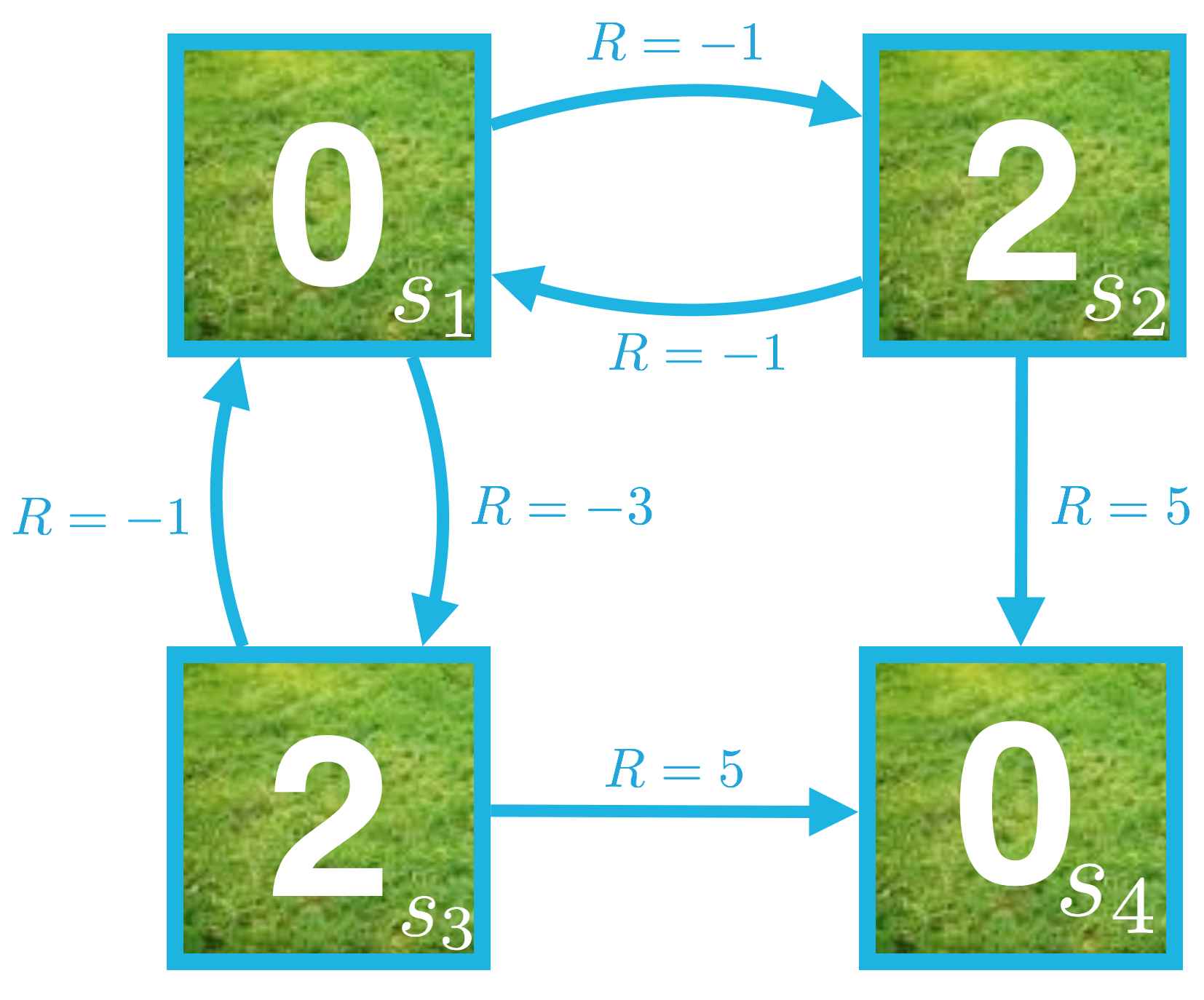
Iterative Policy Evaluation

Note that policy evaluation is guaranteed to converge to the state-value function corresponding to a policy , as long as is finite for each state . For a finite Markov decision process (MDP), this is guaranteed as long as either:
- , or
- if the agent starts in any state , it is guaranteed to eventually reach a terminal state if it follows policy .
Action Values
Use the simple gridworld to practice converting a state-value function to an action-value function
Image below corresponds to the action-value function for the same policy.
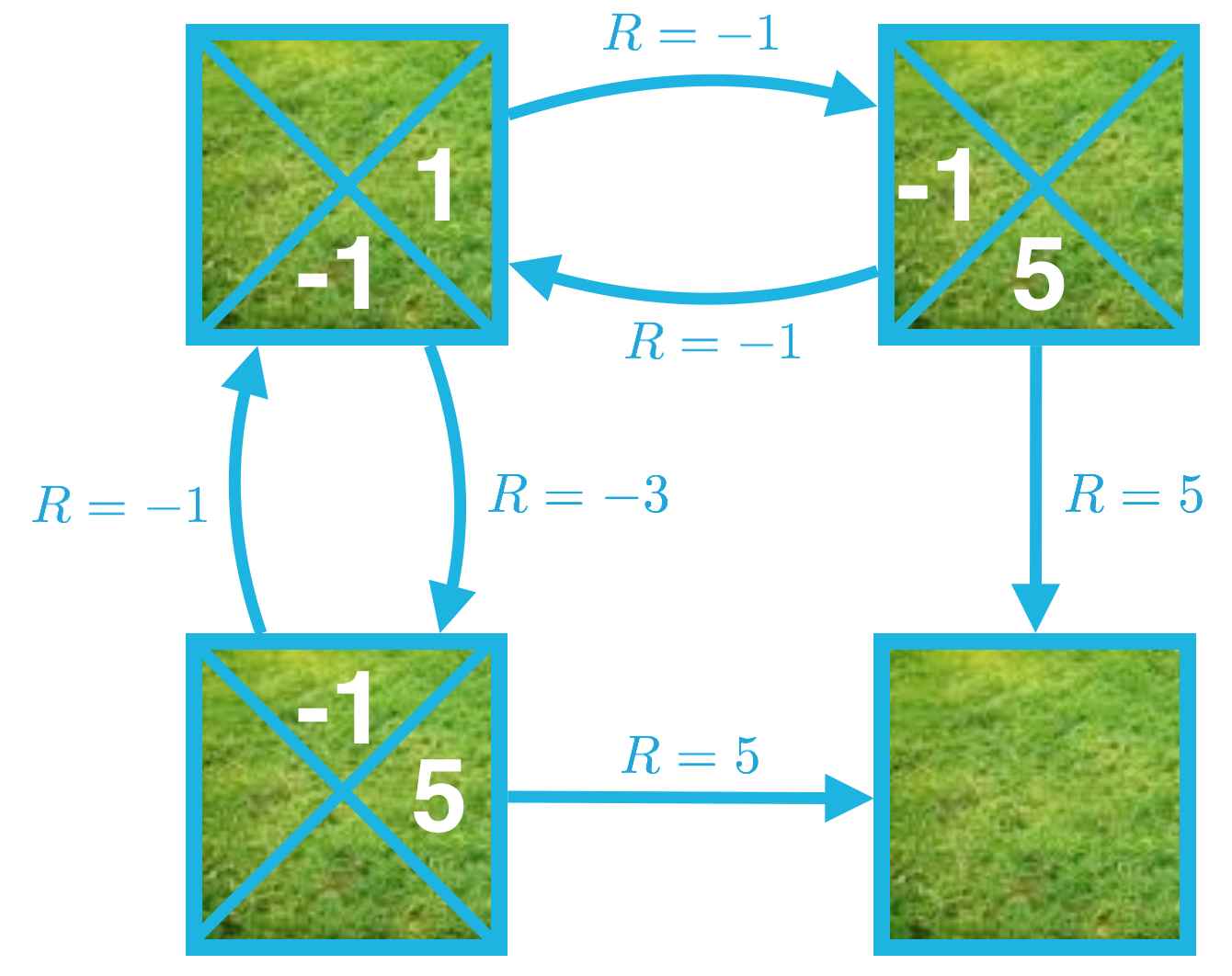
As an example, consider . This action value can be calculated as
where we just use the fact that we can express the value of the state-action pair as the sum of two quantities:
- the immediate reward after moving right and landing on state
- the cumulative reward obtained if the agent begins in state and follows the policy.
For More Complex Environments
In this simple gridworld example, the environment is deterministic. In other words, after the agent selects an action, the next state and reward are 100% guaranteed and non-random. For deterministic environments,
In this case, when the agent is in state s and takes action , the next state and reward can be predicted with certainty, and we must have
In general, the environment need not be deterministic, and instead may be stochastic. This is the default behavior of the FrozenLake environment; in this case, once the agent selects an action, the next state and reward cannot be predicted with certainty and instead are random draws from a (conditional) probability distribution
In this case, when the agent is in state and takes action , the probability of each possible next state and reward is given by . In this case, we must have , where we take the expected value of the sum
Estimation of Action Values
Write an algorithm that accepts an estimate of the state-value function along with the one-step dynamics of the MDP and returns an estimate the action-value function
Use the one-step dynamics of MDP to obtain from . Namely,
holds for all .

Policy Improvement
Our reason for computing the value function for a policy is to help find better policies. Suppose we have determined the value function for an arbitrary deterministic policy . For some state we would like to know whether or not we should change the policy to deterministically choose an action .
Implementation
It is possible to construct an improved (or equivalent) policy , where
For each state , you need to select the action that maximizes the action-value function estimate. In other words,
for all .

In the event that there is some state for which is not unique, there is some flexibility in how the improved policy is constructed.
In fact, as long as the policy satisfies for each and :
It is an improved policy. In other words, any policy that (for each state) assigns zero probability to the actions that do not maximize the action-value function estimate (for that state) is an improved policy.
Policy Iteration

This way of finding an optimal policy is called policy iteration.
Policy iteration is guaranteed to find the optimal policy for any finite Markov decision process (MDP) in a finite number of iterations.

Value Iteration
One drawback to policy iteration is that each of its iterations involves policy evaluation, which may itself be a protracted iterative computation requiring multiple sweeps through the state set. If policy evaluation is done iteratively, then convergence exactly to occurs only in the limit.
In fact, the policy evaluation step of policy iteration can be truncated in several ways without losing the convergence guarantees of policy iteration. One important special case is when policy evaluation is stopped after just one sweep (one update of each state). This algorithm is called value iteration.
In this algorithm, each sweep over the state space effectively performs both policy evaluation and policy improvement. Value iteration is guaranteed to find the optimal policy for any finite MDP.

Note that the stopping criterion is satisfied when the difference between successive value function estimates is sufficiently small. In particular, the loop terminates if the difference is less than for each state. And, the closer we want the final value function estimate to be to the optimal value function, the smaller we need to set the value of .
note that in the case of the FrozenLake environment, values around
1e-8seem to work reasonably well.