Reinforcement Learning
Reinforcement learning is learning what to do—how to map situations to actions—so as to maximize a numerical reward signal. The learner is not told which actions to take, but instead must discover which actions yield the most reward by trying them.
- A policy defines the learning agent’s way of behaving at a given time. Roughly speaking, a policy is a mapping from perceived states of the environment to actions to be taken when in those states.
- A reward signal defines the goal of a reinforcement learning problem. On each time step, the environment sends a single number called the reward to the reinforcement learning agent.
- The reward signal indicates what is good in an immediate sense, a value function specifies what is good in the long run. Roughly speaking, the value of a state is the total amount of reward an agent can expect to accumulate over the future, starting from that state.
- Model mimics the behavior of the environment, or more generally, that allows inferences to be made about how the environment will behave.
Methods for solving reinforcement learning problems that use models and planning are called model-based methods, as opposed to simpler model-free methods that are explicitly trial-and-error learners.
Reinforcement learning uses the formal framework of Markov decision processes to define the interaction between a learning agent and its environment in terms of states, actions, and rewards. We will learn problem formulation with finite Markov Decision Processes and its main ideas including Bellman equations and value functions.
Three fundamental classes of methods for solving finite Markov decision problems:
- Dynamic programming
- Monte Carlo methods
- Temporal difference learning
The methods also differ in several ways with respect to their efficiency and speed of convergence.
Dynamic programming methods are well developed mathematically, but require a complete and accurate model of the environment.
Monte Carlo methods don’t require a model and are conceptually simple, but are not well suited for step-by-step incremental computation.
Temporal-difference methods require no model and are fully incremental, but are more complex to analyze.
If actions are allowed to affect the next situation as well as the reward, then we have the full reinforcement learning problem.
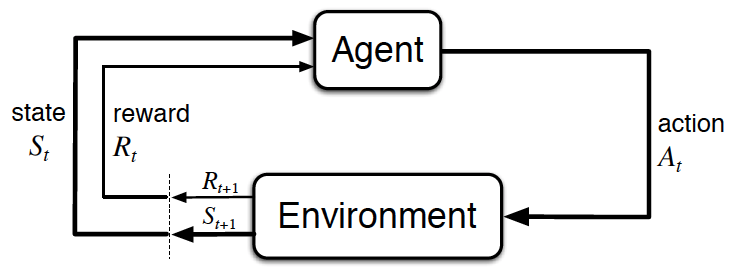
- The learner and decision maker is called the agent.
- The thing it interacts with, comprising everything outside the agent, is called the environment.
- Thus RL framework is characterized by an agent learning to interact with its environment.
- At each time step, the agent receives the environment's state (the environment presents a situation to the agent), and the agent must choose an appropriate action in response. One time step later, the agent receives a reward (the environment indicates whether the agent has responded appropriately to the state) and a new state.
- All agents have the goal to maximize expected cumulative reward, or the expected sum of rewards attained over all time steps.
The state must include information about all aspects of the past agent–environment interaction that make a difference for the future. If it does, then the state is said to have the Markov property.
Episodic vs. Continuing Tasks
- A task is an instance of the reinforcement learning (RL) problem.
- Continuing tasks are tasks that continue forever, without end.
- Episodic tasks are tasks with a well-defined starting and ending point.
- In this case, we refer to a complete sequence of interaction, from start to finish, as an episode.
- Episodic tasks come to an end whenever the agent reaches a terminal state.
The Reward Hypothesis
- Reward Hypothesis: All goals can be framed as the maximization of (expected) cumulative reward.
Cumulative Reward
The return at time step t is The agent selects actions with the goal of maximizing expected (discounted) return.
Discounted Return
- Discounting: The agent tries to select actions so that the sum of the discounted rewards it receives over the future is maximized.
- The discounted return at time step t is
- The discount rate is something that you set, to refine the goal that you have the agent.
- It must satisfy 0 <= <= 1
- If , the agent only cares about the most immediate reward.
- If , the return is not discounted.
- For larger values of , the agent cares more about the distant future. Smaller values of result in more extreme discounting, where - in the most extreme case - agent only cares about the most immediate reward.
MDPs and One-Step Dynamics
- The state space is the set of all (nonterminal) states.
- In episodic tasks, we use to refer to the set of all states, including terminal states.
- The action space is the set of possible actions. (Alternatively, refers to the set of possible actions available in state
- The one-step dynamics of the environment determine how the environment decides the state and reward at every time step. The dynamics can be defined by specifying
- A (finite) Markov Decision Process (MDP) is defined by:
- a (finite) set of states (or , in the case of an episodic task)
- a (finite) set of actions
- a set of rewards
- the one-step dynamics of the environment
- the discount rate
Bellman Equations
In this gridworld example, once the agent selects an action,
- it always moves in the chosen direction (contrasting general MDPs where the agent doesn't always have complete control over what the next state will be), and
- the reward can be predicted with complete certainty (contrasting general MDPs where the reward is a random draw from a probability distribution).
In this simple example, we saw that the value of any state can be calculated as the sum of the immediate reward and the (discounted) value of the next state.
Alexis mentioned that for a general MDP, we have to instead work in terms of an expectation, since it's not often the case that the immediate reward and next state can be predicted with certainty. Indeed, we saw in an earlier lesson that the reward and next state are chosen according to the one-step dynamics of the MDP. In this case, where the reward r and next state s′ are drawn from a (conditional) probability distribution , the Bellman Expectation Equation (for expresses the value of any state s in terms of the expected immediate reward and the expected value of the next state:
Calculating the Expectation
In the event that the agent's policy π is deterministic, the agent selects action when in state , and the Bellman Expectation Equation can be rewritten as the sum over two variables ():
In this case, we multiply the sum of the reward and discounted value of the next state by its corresponding probability and sum over all possibilities to yield the expected value.
If the agent's policy is stochastic, the agent selects action with probability when in state , and the Bellman Expectation Equation can be rewritten as the sum over three variables :
In this case, we multiply the sum of the reward and discounted value of the next state by its corresponding probability and sum over all possibilities to yield the expected value.
Policies
-
A deterministic policy is a mapping . For each state , it yields the action (a \in A) that the agent will choose while in state .
-
A stochastic policy is a mapping . For each state and action , it yields the probability that the agent chooses action while in state .
State-Value Functions
- The state-value function for a policy is denoted . For each state , it yields the expected return if the agent starts in state and then uses the policy to choose its actions for all time steps. That is,
We refer to as the value of state under policy .
- The notation denotes the expected value of a random variable given that the agent follows policy , and is any time step.
Optimality
-
A policy is defined to be better than or equal to a policy if and only if for all .
-
An optimal policy satisfies for all policies π. An optimal policy is guaranteed to exist but may not be unique.
- All optimal policies have the same state-value function called the optimal state-value function.
Action-Value Functions
- The action-value function for a policy is denoted . For each state and action , it yields the expected return if the agent starts in state , takes action , and then follows the policy for all future time steps. That is,
We refer as the value of taking action in state under a policy (or alternatively as the value of the state-action pair s,a).
- All optimal policies have the same action-value function , called the optimal action-value function.
Optimal Policies
- Once the agent determines the optimal action-value function , it can quickly obtain an optimal policy by setting: