
AOT - Creating current publicly available information in English
June 01, 2019
If you’re a fan of Attack on Titan, you’ve likely noticed the “Current Publicly Available Information” slides that appear between episodes. While this information is often mentioned in dialogues, the visuals in the show provide deeper insights.
I came across a website that compiled these slides, which was great! But it had a couple of drawbacks:
- The English translations appeared beside small image thumbnails, making them hard to read.
- Clicking an image caused the text to disappear, which was inconvenient.
If I click on image i’ll lose the text, so I did some web scraping and use OpenCV to modify image programatically to include English text at the bottom of the image.
let’s look at the steps involved:
- Scrape Image Links with BeautifulSoup
By inspecting the page, I realised the images have href attribute and also to remove other unwanted links I have put condition based on length which in our case satisfy the image links.
from bs4 import BeautifulSoup
from urllib.request import urlopen
import re
links = ['https://attackontitan.fandom.com/wiki/Current_Publicly_Available_Information/Anime',
'https://attackontitan.fandom.com/wiki/Current_Publicly_Available_Information/Anime/Season_2',
'https://attackontitan.fandom.com/wiki/Current_Publicly_Available_Information/Anime/Season_3',
'https://attackontitan.fandom.com/wiki/Current_Publicly_Available_Information/Anime/OVA']
href_lines = []
for i in range(4):
html_page = urlopen(links[i])
soup = BeautifulSoup(html_page, 'lxml')
for link in soup.findAll('a'):
if link.get('href') is not None and len(link.get('href')) > 109 and len(link.get('href')) < 115 :
href_lines.append(link.get('href').strip())
with open('extracted-img-links.txt', 'w') as file:
for line in href_lines:
file.write(line+'\n')The image links are saved to a file.
- Once I had all the image links, I used
urllib.requestto download them locally.
import urllib.request
import os
img_count = 0
file_list = "C:/Users/Vinay/Pictures/AOT/{0}.png"
with open("extracted-img-links.txt") as f:
for image in f:
try:
urllib.request.urlretrieve(image.strip(), file_list.format(img_count))
img_count += 1
except IOError:
print(image + " does not exist")Now we have original images saved.
- Next step is to download all the respective text for the image which was beside the thumbnail in website. Below code fetches all paragraph inside a table we are interested in.
OpenCV doesn’t have method that supports text with quotes so we have to explicitly remove them before saving to file.
from bs4 import BeautifulSoup, NavigableString
from urllib.request import urlopen
import re
links = ['https://attackontitan.fandom.com/wiki/Current_Publicly_Available_Information/Anime',
'https://attackontitan.fandom.com/wiki/Current_Publicly_Available_Information/Anime/Season_2',
'https://attackontitan.fandom.com/wiki/Current_Publicly_Available_Information/Anime/Season_3',
'https://attackontitan.fandom.com/wiki/Current_Publicly_Available_Information/Anime/OVA']
paras = []
for i in range(4):
html_page = urlopen(links[i])
soup = BeautifulSoup(html_page, 'lxml')
tables = soup.findChildren('table')
my_table = tables[0]
rows = my_table.findChildren(['th', 'tr'])
for row in rows:
cells = row.findChildren('td')
for cell in cells:
for p in cell.findAll('p'):
str = p.text.replace("'", "")
paras.append(str.replace('"', ''))
with open('extracted-p.txt', 'w') as file:
for line in paras:
file.write(line+'\n')- I wanted to automate whole process but due to non-uniform order of text, we need manual intervention to verify if there are images which have desciption in other than
<p>.
I found out one case where instead of paragraph, <li> was used - so I just added text in respective line so that our images are named as index on which description is saved.
Now we can clean up extracted paragraph by removing empty lines.
def isLineEmpty(line):
return len(line.strip()) == 0
with open('extracted-para.txt') as file:
info = file.readlines()
with open('extracted.txt', 'w') as file:
for line in info:
if not isLineEmpty(line):
file.write(line)- Overlay Text on Images using OpenCV
Finally, I added a bottom border to each image and overlaid the corresponding English text. Since OpenCV doesn’t wrap text automatically, I added logic to manually break lines.
import sys
import cv2 as cv
bottom = 100
borderType = cv.BORDER_CONSTANT
font = cv.FONT_HERSHEY_SIMPLEX
with open('extracted.txt') as file:
info = file.readlines()
for i in range(1,85):
src = cv.imread('C:/Users/Vinay/Pictures/AOT/{0}.png'.format(i), cv.IMREAD_COLOR)
dst = cv.copyMakeBorder(src, 0, bottom, 0, 0, borderType, None, 0)
text = info[i].strip()
if(len(text) > 300):
cv.putText(dst,text[0:150],(10, dst.shape[0]-75), font, 0.75, (255,255,255), 1, cv.LINE_AA)
cv.putText(dst,'-'+text[150:300],(10, dst.shape[0]-50), font, 0.75, (255,255,255), 1, cv.LINE_AA)
cv.putText(dst,'-'+text[300:],(10, dst.shape[0]-25), font, 0.75, (255,255,255), 1, cv.LINE_AA)
elif(len(text) > 150):
cv.putText(dst,text[0:150],(10, dst.shape[0]-64), font, 0.75, (255,255,255), 1, cv.LINE_AA)
cv.putText(dst,'-' + text[150:],(10, dst.shape[0]-32), font, 0.75, (255,255,255), 1, cv.LINE_AA)
else:
cv.putText(dst,text,(10, dst.shape[0]-50), font, 0.75, (255,255,255), 1, cv.LINE_AA)
cv.imwrite('C:/Users/Vinay/Pictures/AOT/sub/{0}.png'.format(i), dst)Here’s how the final image looks with the English text embedded directly:
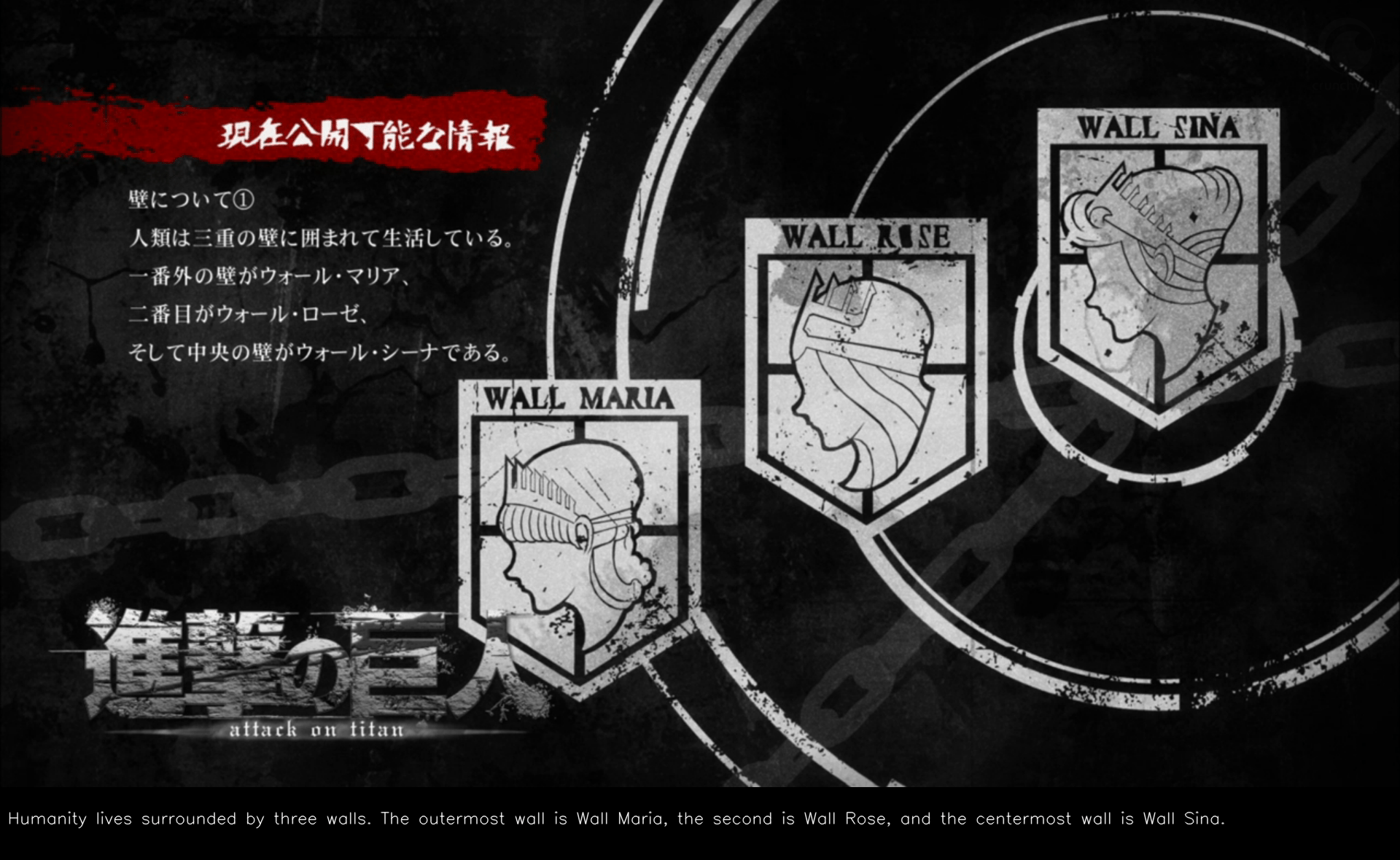
Notice the English description clearly visible at the bottom of the image!
Summary
By combining web scraping with OpenCV image processing, I built a personal archive of Attack on Titan’s “Current Publicly Available Information” slides — with readable English captions embedded directly into the image.
This approach solved:
- The issue of small text thumbnails,
- The inconvenience of losing text when viewing images.
